


Howdy there. Long time no see.
If you’ve been reading this blog over the past few weeks, you’ll have noticed the byline has been almost entirely Toby’s. That’s because I’ve been head-down with our existing clients — we had to rebalance aggressively to capitalize on the market fire sale triggered by the fear that MSCI was going to downgrade Indonesia from Emerging Markets into Frontier Markets status, compounded by the Iran-war shock and the general panic that came with them.
A lot of names we had been tracking in our watchlist suddenly fell into our buy zone, and when that happens, writing blog posts takes a backseat to actually allocating capital. That work is now largely behind us. I can go back to writing regularly.
And I want to start with something that, if I’m being honest with you, I don’t bring up enough.
I have never worked a single day as a professional equity analyst.
My degree is in Computer Engineering from the Hong Kong University of Science & Technology. My professional career before Recompound was software engineering and data science — most recently, building credit-scoring engines.

Everything I know about investing is otodidak: self-taught through reading, through making real losses in the market (a tuition fee you can only pay in cash), and — when I decided this wasn’t a hobby anymore — through obtaining my Penasihat Investasi (PI) license from OJK.
That’s the pedigree. If you want to verify, my LinkedIn is public.
The paradox
I bring this up because one of the most common questions I get when meeting someone new is: “Wait, you have an engineering and data-science background and you do value investing? Shouldn’t you be doing quant trading?”
It’s a fair question. On paper, my background fits quantitative strategies much more naturally — statistical arbitrage, high-frequency patterns, alphas hidden in the noise, complicated maths all the way down. That was the path of least resistance. I didn’t take it.
The honest reason is that value investing clicked for me in a way that quant never did. And what made it click was not Warren Buffett. It was a concept I had already been using for years in a completely different context, dressed up in different words.
That concept is Margin of Safety.
What Margin of Safety actually is
Most retail investors I meet misunderstand what Margin of Safety actually is. They think it’s a tool for calculating target price — “if fair value is 1,500 and MoS is 30%, I buy at 1,050.” That’s half-true at best. It is also backwards.
Margin of Safety is not a number that tells you how much money you’re going to make.
Margin of Safety is a number that tells you how much you can survive being wrong.
Wrong about what? Wrong about everything. Wrong about the company’s moat. Wrong about the owner’s integrity. Wrong about the commodity cycle. Wrong about the macro regime. Wrong about the discount rate you used because you forgot to check the risk-free rate had moved. Wrong because some black swan none of us priced in showed up uninvited.
The whole point of MoS is to bake humility into the assessment — we don’t know what we don’t know — and let the buffer do the work when we’re inevitably wrong about something.
And that is exactly what I had been doing as an Machine Learning engineer, except we called it something else.
The Machine Learning analog: Regularization
In machine learning, when you train a model on data, your default loss function looks something like:
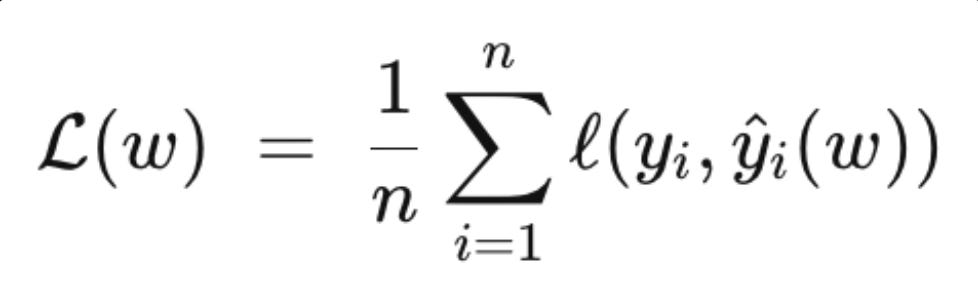
where w is the vector of model weights. You minimize that loss, and you get the best-fit model for your training data.
Except — there is a problem. The best-fit model for the training data is often a terrible model for the real world. It latches onto noise, memorizes rubbish, and collapses the moment it sees unfamiliar inputs. We call this overfitting. The model is too confident in patterns that aren’t real.
The fix is regularization. You add a penalty term to the loss function:
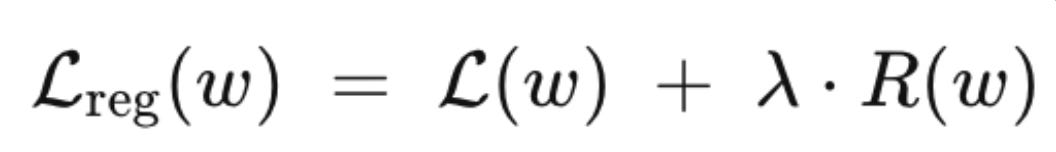
where R(w) is some measure of model complexity. The two most common forms are L2 (ridge), which penalizes large weights:
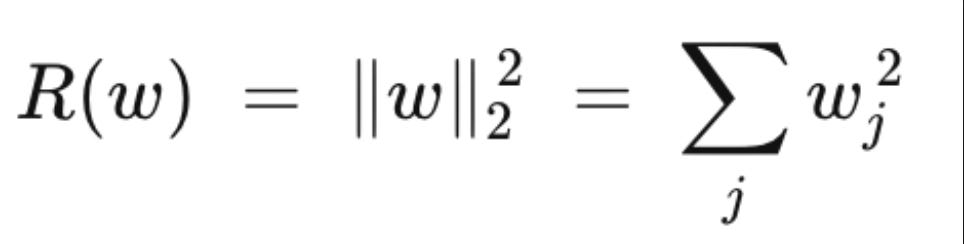
and L1 (lasso), which drives many weights to exactly zero:
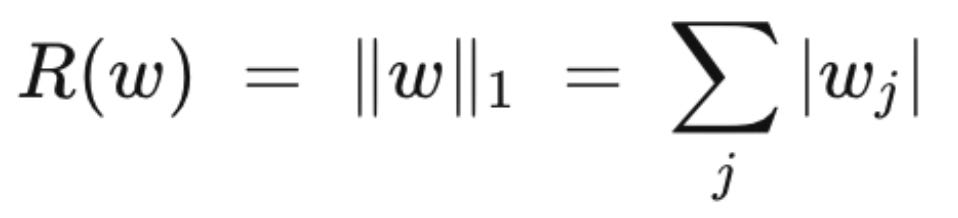
The coefficient λ controls how much you care about fitting the training data versus keeping the model humble. Crank λ up, and your model will have worse training-set performance but better real-world performance. Because — and this is the sentence I want you to sit with for a second —
The real world is not the training set.
That is literally Margin of Safety, just under a different name.
Why the analogy goes deeper than it looks
A value investor building a thesis is doing what an ML engineer does training a model. You construct a mental representation — this business earns X, grows at Y, the owner behaves like Z, the commodity cycle does W — and you check how well it fits the data you have. If your thesis is sophisticated enough and your data looks clean enough, you can convince yourself very precisely where the stock should trade.
But your data is the training set. The real world is the test set. The real world has Iran-war shocks, RKAB quota surprises, sudden waves of foreign money leaving Indonesia when global index providers change their mind about us, commodity cycles that last one year longer or shorter than the prior ten. You cannot regularize these away. You can only prepare for them.
Howard Marks puts it more memorably than I can:
“Never forget the six-foot-tall man who drowned crossing the stream that was five feet deep on average.”
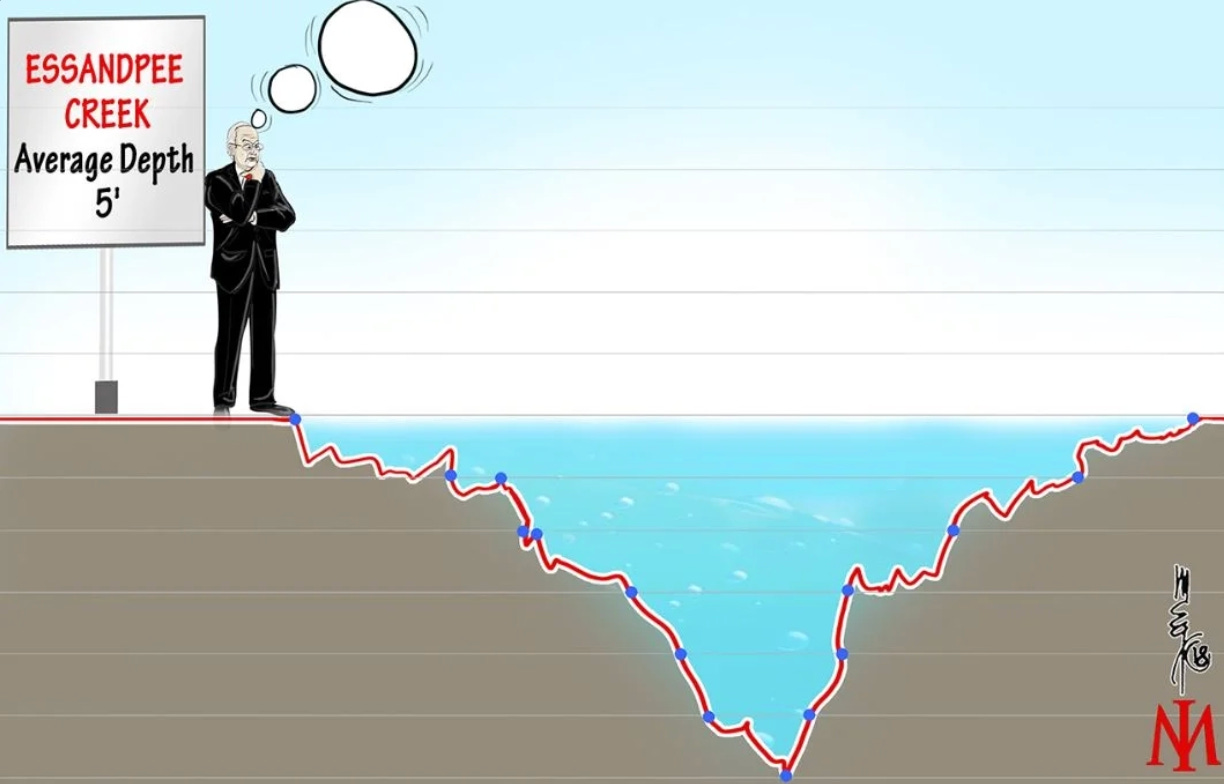
The stream is the training data. On average it is crossable. The drowning happens at the deep spot that the average conceals. Survival depends on preparing for the worst point on the curve, not the mean of the curve. A strategy that works in normal weather but dies in the tail is not a strategy — it is a delayed obituary.
Regularization — in ML and in investing — is the penalty you willingly pay for that preparation. You give up some upside in exchange for not drowning.
The second analog: diversification as regularization
There is a second place the analogy runs deep, and it is where I want to gently push back on a pattern I see often in Indonesian retail value-investing circles.
Let me be clear about what I am not arguing.
At Recompound we run roughly five to twelve names at any given time.
By most global measures, that is already a concentrated portfolio — a typical US mutual fund holds eighty or more. Five to ten names is a perfectly healthy balance of conviction and diversification. It is what we do, and we are comfortable with it.
What I want to flag is not five or ten. It is one, two, or three.
The standard Buffett-inspired advice is “if you really understand what you own, you only need a handful.” Some retail investors I meet take this much further than Buffett ever intended and end up with one, two, maybe three stocks that represent 80 to 100% of their net worth. Almost always these are people who have read one or two investing books, found their big conviction, and gone all-in because they “know” the thesis.
I understand the impulse — I have felt it myself. I still think it is dangerous.
To see why, two more lessons from machine learning are worth borrowing.
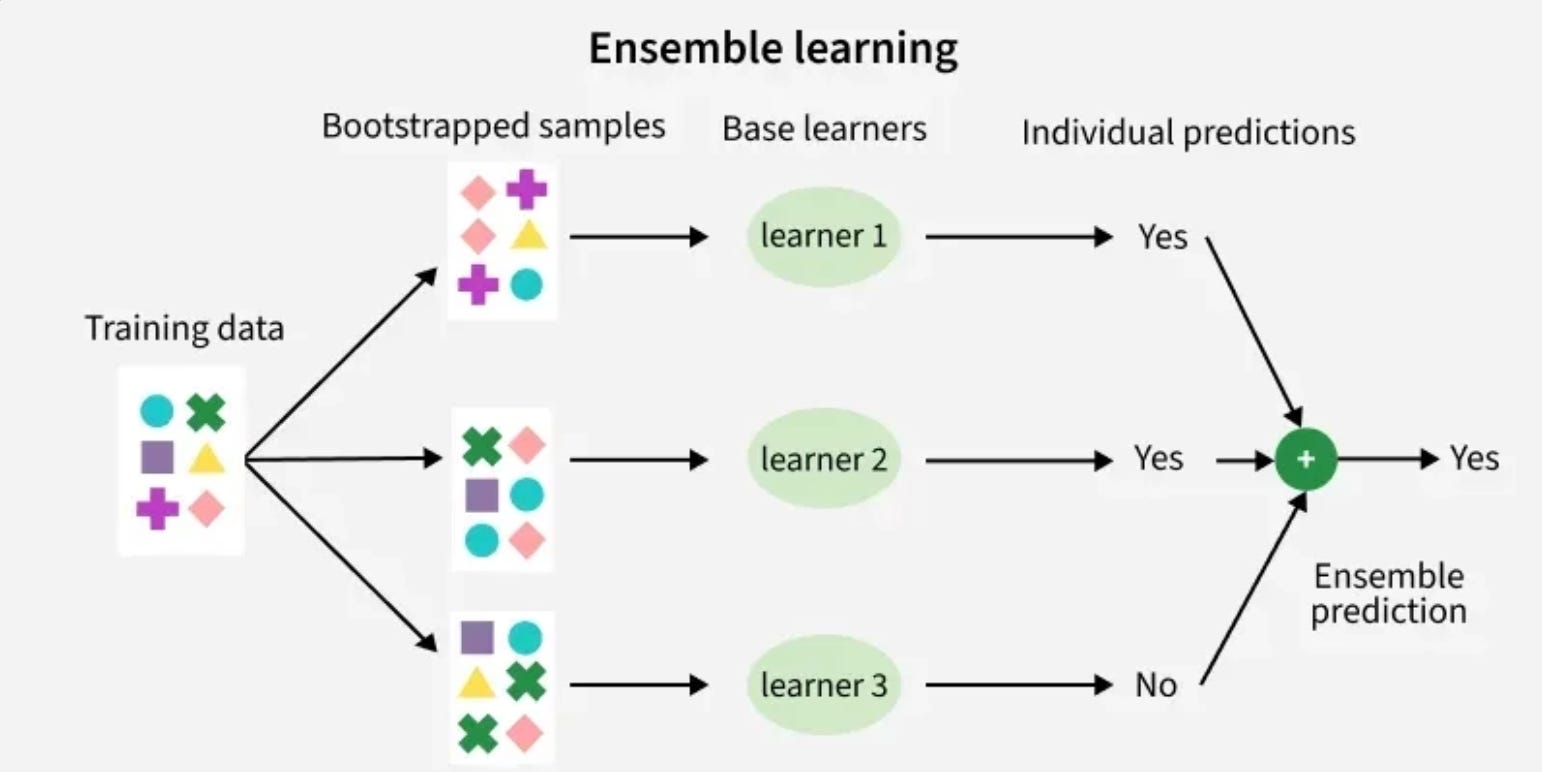
The first is that an ensemble of decent models almost always beats a single brilliant one on out-of-sample data. Random forests beat the best single decision tree. Averaged networks beat the best single network. Boring, but true.
The second is dropout — the practice of randomly disabling neurons during training. Models trained with dropout are more robust than models that aren't, because they are forced to not over-rely on any single path.
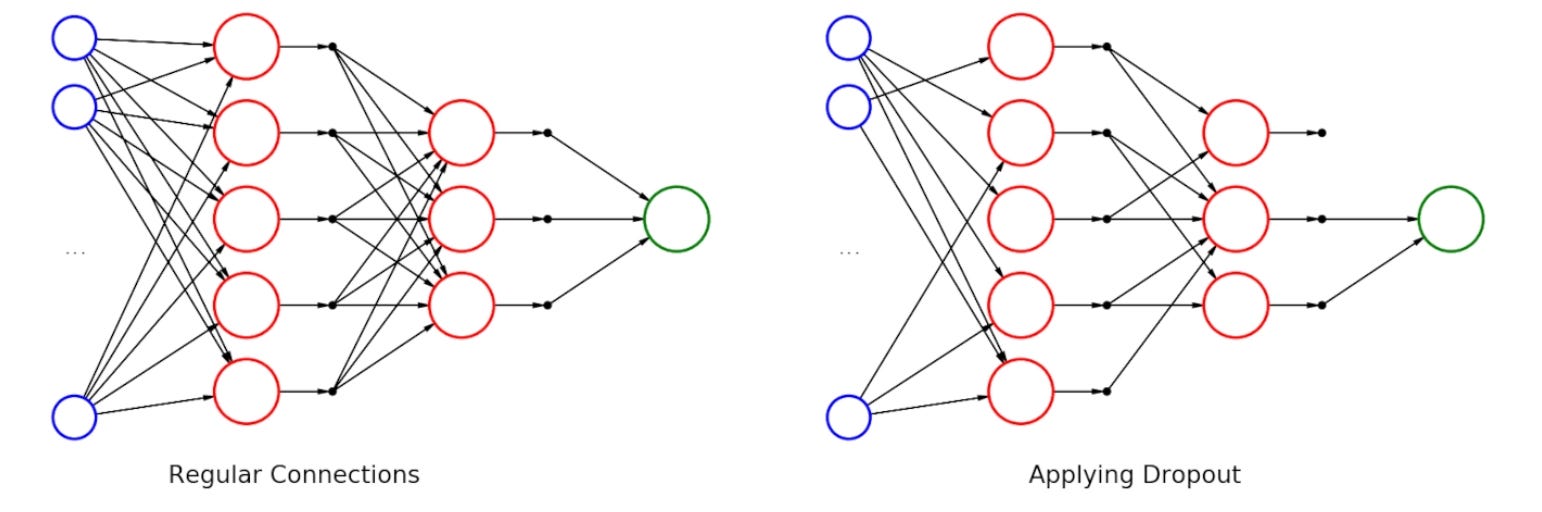
The investment analog writes itself. A one-to-three-stock portfolio is a single model, even a brilliant one — and we know what happens to a single brilliant model when the data it didn’t see shows up. A ten-name portfolio with uncorrelated exposures and no two names sharing the same failure mode is an ensemble. And position-sizing discipline that caps every name at a hard max porsi porto is dropout for investors: you force yourself to survive even when one conviction quietly dies.
MoS on each name protects against the specific failure mode of that name. Diversification across names protects against the category of failure you didn’t see coming. Both layers are needed. Neither is sufficient on its own.
Your MoS on that one stock may be excellent. But when a tail-risk event arrives — and it will — a huge MoS on a single name is still a single-name bet. You do not die. You simply stop existing as an investor.
Concentration gives you alpha when you’re right. Diversification gives you survival when you’re wrong. I have been wrong enough in my life — in my ML jobs and in the market — to not trust myself to be right every time on just one or two names.
The cautionary tale: LTCM
The story I keep coming back to is Long-Term Capital Management.
LTCM’s partners included Myron Scholes and Robert Merton — actual Nobel laureates in economics. Their models were more sophisticated than anything I will build in my lifetime. Their training data was cleaner, their maths sharper, their execution more disciplined than 99% of market participants.
They blew up in 1998. A few sigma events that “couldn’t happen” — Russian sovereign default — happened, and the fund had to be rescued by a consortium of banks to prevent systemic contagion.
LTCM did not fail because they were stupid. They failed because they had trained on a world that didn’t include the tail, and then levered up based on the confidence that beautifully-fit model gave them. They had an extraordinarily well-fit model with almost zero regularization.
Kita bukan dewa was a lesson they hadn’t internalized yet.
When I read about LTCM — and I read about it often, the way some people re-read tragic novels — I do not see a story about excessive pride and self confidence.
I see a story about regularization coefficients set too low.
Closing
So here’s the thing. If you have an engineering or a data-science background and you’re wondering whether value investing is for people like us — I promise you it is.
More naturally than quant, actually.
Quant, in its most common form, is optimization without humility (in my humble opinion).
Value investing, done properly, is optimization with a regularizer. You are not trying to build the best model of the market. You are trying to build a model that survives what you did not expect.
Margin of Safety on each position. Diversification across positions. Position sizing that respects your own ignorance. These are not just “be careful with money” platitudes your parents told you.
They are λ’s — little penalty coefficients in the loss function of your life’s capital.

Turn them too low and you will outperform in the training set — and die in production.
Turn them high enough and, like any well-regularized model, you will be slightly less impressive on paper. But you will still be around to keep compounding ten years from now.
And compounding, really, is the only game that matters.
See you on the next one.
Haha, loved the ML analogy, especially the regularization framing.
I come from a CS/AI background too, and I agree that the real world is not equal to the training set, the idea translates very well into investing.
That said, I’m not fully convinced that quant is “optimization without humility.” Well-designed systems are usually built on the assumption that we’re wrong more often than we think, which is why constraints like position sizing and diversification exist in the first place.
Sometimes removing discretion is exactly what keeps us from overfitting.